CDK Module dependencies #2
A bit over 2 years ago I published a UML diagram showing the dependencies between CDK modules. Since then I lot of new modules have been defined, added or factored out from the extra module (click to zoom):
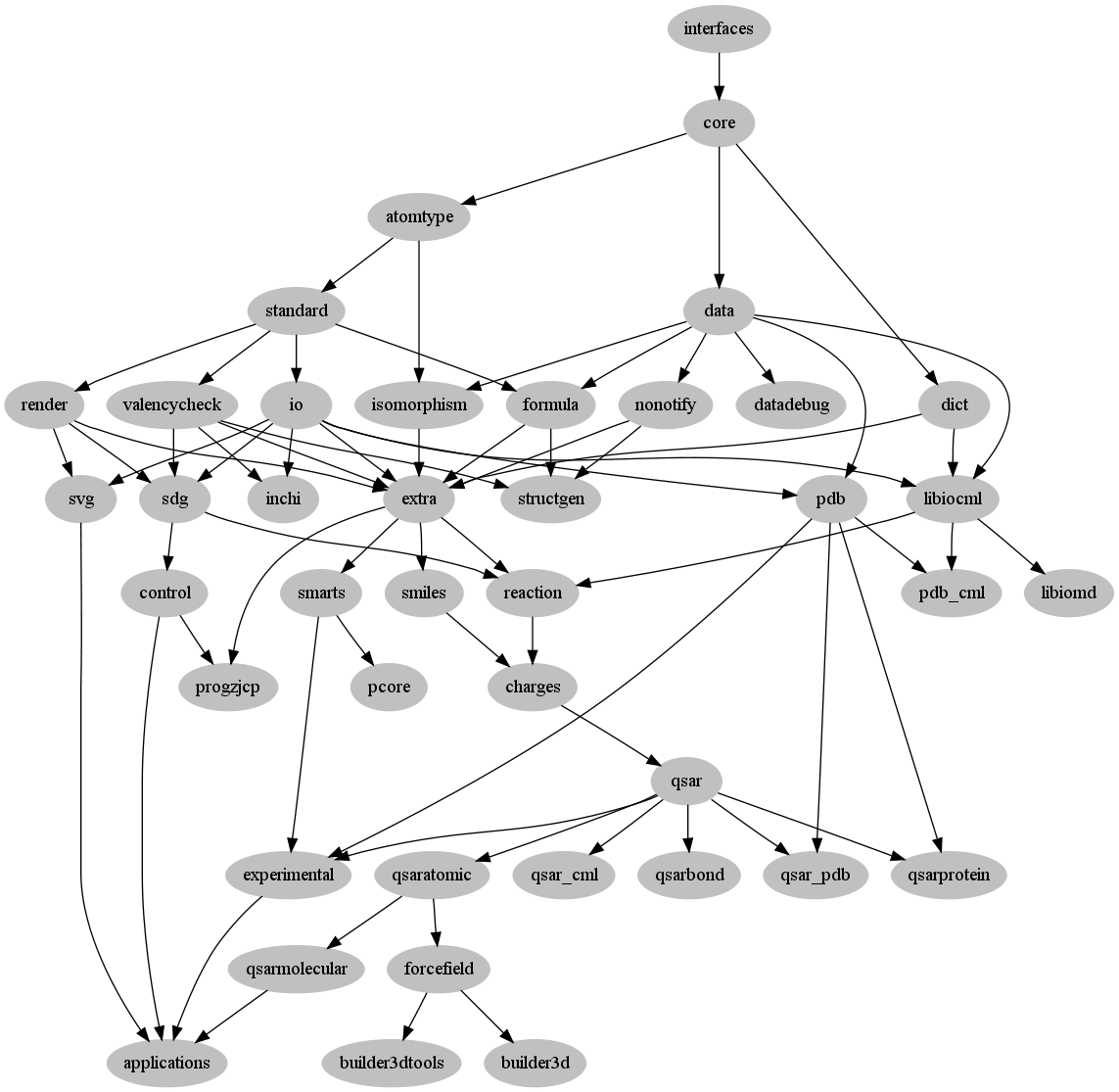
These kind of diagrams help us maintain the library, and apply some design goals, as explained in the first post on this.
If one compares the two diagrams, one sees that fewer code depends on the data module, but it is also clear that still a
lot of them do. Another issue that had not properly addressed yet, is that a lot of modules still depend on the extra module,
which aggregates everything that had not been assigned elsewhere.
Parallelism
This diagram also helped me use the [Ant
Now, graph analysis could pinpoint the most troublesome nodes, but it would not surprise me that extra would be amongst them. But the following items are worth looking at too:
- why does
qsarhave to depend oncharges? - why does
sdg(the 2D layout code) depends oniocode? - can
isomorphismandformulabe made independent ofdata? - why does
reactiondepend onsdg? - why does
forcefielddepend onqsaratomic?
Some of these issues are rather practical, but it is these kind of analyses that help us clean up the CDK library.