-
RDF, Jena, Bioclipse, Eclipse, Zest #2: icons and an extension point
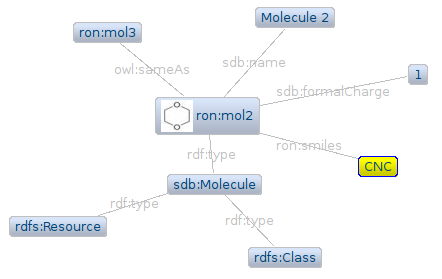
Jonathan worked this week on new features for the Bioclipse RDF editor (see these two earlier items). This version still does not edit, but only display using Zest. Jonathan created for me an extension point so that anyone can make the editor aware of domain objects, by simply registering the extension implementation along with the rdf:Class URI of the rdf:type of an object. This fixes the problem of having to hardcode dependencies of the RDF editor on all the domain code, as was the case earlier.
-
Dutch contribution to the Crystallography Open Database at risk?
The Dutch company PANalytical has made their HighScore software available (some details in this README) for use in the Crystallography Open Database.
-
Further statistics on the papers citing the CDK
I already gave a wordle of the titles of papers citing the first CDK paper. Below follows some additional statistics: the number of papers that use a particular CDK package (51). Now, this numbers are a bit rough, and surely any paper that uses the CDK is bound to use the IO or SMILES package too. Additionally, for 10 papers I was not sure what CDK functionality they used, so I assigned those to the root package.
-
Citing the Chemistry Development Kit
Two weeks ago, a paper by Peter Ertl was published about Molecular structure input on the web (doi:10.1186/1758-2946-2-1). In this paper, he discusses the state of things and describes his contribution to this field, the JME Molecule Editor. The article also cites the CDK, but only the website and not one of the two papers (doi:10.1021/ci025584y, or doi:10.2174/138161206777585274). This is not an isolated case, but a common pattern. In principle, the proper work is cited, and nothing is wrong. Practically it means, that a citation to the CDK website does not show up in the citation network. This is not a problem caused by these papers, but merely by the nature current citation databases work: they only count citations between journal articles, and only sometimes extend to books or conference abstracts.