9. Search engine optimization¶

9.1. Main Objectives¶
The main purpose of this recipe is:
to describe what
search engine optimizationis and show how to implement markup with theSchema.orgvocabulary, andBioschemasextension, to improve page discovery and visibility by web page indexers.
There are sub-recipes for embedding search engine optimization into specific web pages about a specific type or resource:
Resource specific page (Gene, Molecular Entity, Protein)
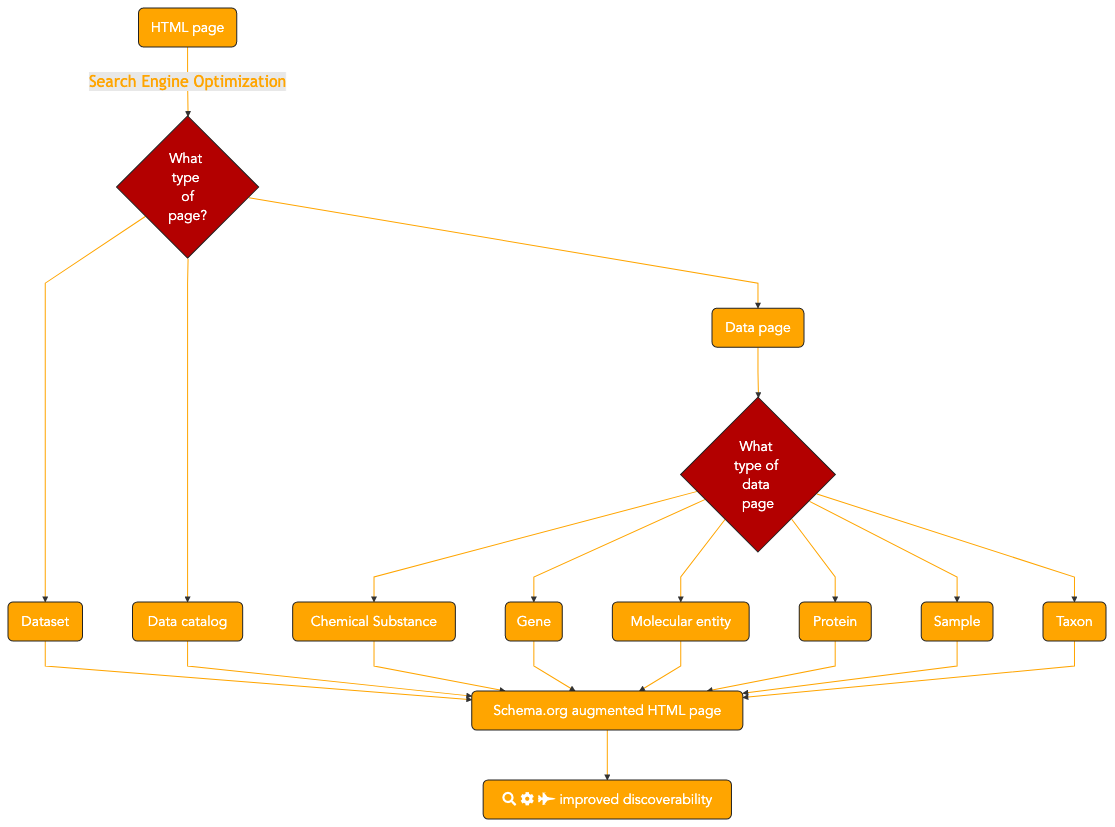
9.3. Capability & Maturity Table¶
Capability |
Initial Maturity Level |
Final Maturity Level |
|---|---|---|
Findabililty |
minimal |
repeatable |
Interoperability |
minimal |
9.4. Main body of the recipe¶
9.4.1. Finding web pages¶
Providers of content for the Internet serve documents formatted or rendered in HTML format. The web pages are hosted on servers, which are accessed via the HTTP protocol. HTML pages can be styled with cascading stylesheets (CSS) and interactivity can be delivered via scripting languages such as Javascript.
With billions of web pages served, a key issue is finding content. To assist in this task, search engines (e.g. Bing, Google, Yandex, Qwantt) have been built. They work by crawling the web, performing brute force keyword indexing or specific files served by the server (e.g. site map), or by targeting specific data structures embedded in the web pages themselves.
9.4.2. What is search engine optimization¶
Search engine index pages based on their content, as identified by web crawlers. So any misclassification or errors in concept identification can affect where a given pages appears in a search results. Various techniques have been therefore been development by website designers, maintainers and engineers to improve ranking in search results. As ranking in search results significantly impact trafic to a web site and possibly revenues, especially if these are dependent on advertising, search engine optimization covers any of the practices which aim at improving the position of a web page in a search result.
9.4.3. Schema.org Vocabulary¶
A few years back, a consortium of search engines decided to combine forces to generate a structured vocabulary to identify and annotation entities, so search engine can index those more efficiently, bringing the power of semantics in the picture. The priorities for content addition to this vocabulary are defined by various factors, mostly driven between content advertising and relevance. Compared to plain keyword based indexing, annotation with structured vocabulary affords gains such as query expansion or improved content validation.
9.4.4. How does Schema.org work in practice:¶
The principle is actually fairly simple. It relies on embedding machine readable content into the HTML file. A variety of options are available (RDFa, microformat, JSON-LD). JSON-LD is widely recommended as the most suitable approach.
Below is a regular plain vanilla HTML page providing information about an scientific journal article.
<!-- A list of the issues for a single volume of a given periodical. -->
<div>
<h1>The Lancet</h1>
<p>Volume 376, July 2010-December 2010</p>
<p>Published by Elsevier
<ul>
<li>ISSN: 0140-6736</li>
</ul>
<h3>Issues:</h3>
<ul>
<li>No. 9734 Jul 3, 2010 p 1-68</li>
<li>No. 9735 Jul 10, 2010 p 69-140</li>
</ul>
</div>
Now, we are presenting the same information augmented with the JSON-LD file using Schema.org ScholarlyArticle profile. Note how the file is provided with the HTML script tag
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@graph": [
{
"@id": "#issue",
"@type": "PublicationIssue",
"issueNumber": "5",
"datePublished": "2012",
"isPartOf": {
"@id": "#periodical",
"@type": [
"PublicationVolume",
"Periodical"
],
"name": "Cataloging & Classification Quarterly",
"issn": [
"1544-4554",
"0163-9374"
],
"volumeNumber": "50",
"publisher": "Taylor & Francis Group"
}
},
{
"@type": "ScholarlyArticle",
"isPartOf": "#issue",
"description": "The library catalog as a catalog of works was an infectious idea, which together with research led to reconceptualization in the form of the FRBR conceptual model. Two categories of lacunae emerge--the expression entity, and gaps in the model such as aggregates and dynamic documents. Evidence needed to extend the FRBR model is available in contemporary research on instantiation. The challenge for the bibliographic community is to begin to think of FRBR as a form of knowledge organization system, adding a final dimension to classification. The articles in the present special issue offer a compendium of the promise of the FRBR model.",
"sameAs": "https://doi.org/10.1080/01639374.2012.682254",
"about": [
"Works",
"Catalog"
],
"pageEnd": "368",
"pageStart": "360",
"name": "Be Careful What You Wish For: FRBR, Some Lacunae, A Review",
"author": "Smiraglia, Richard P."
}
]
}
</script>
JSON-LD is an official serialization of RDF and the document is recognized as a graph holding a set of triples. The availability of such semantic statements from a web page are exploited by the indexing algorithms of search engines to provide improved search results.
9.4.5. Tools supporting creation and validation of structured data¶
Google has produced an online tool allowing developers to test the annotation they produce before rolling them out to production.
The tool is known as the Google Structured Data Testing Tool
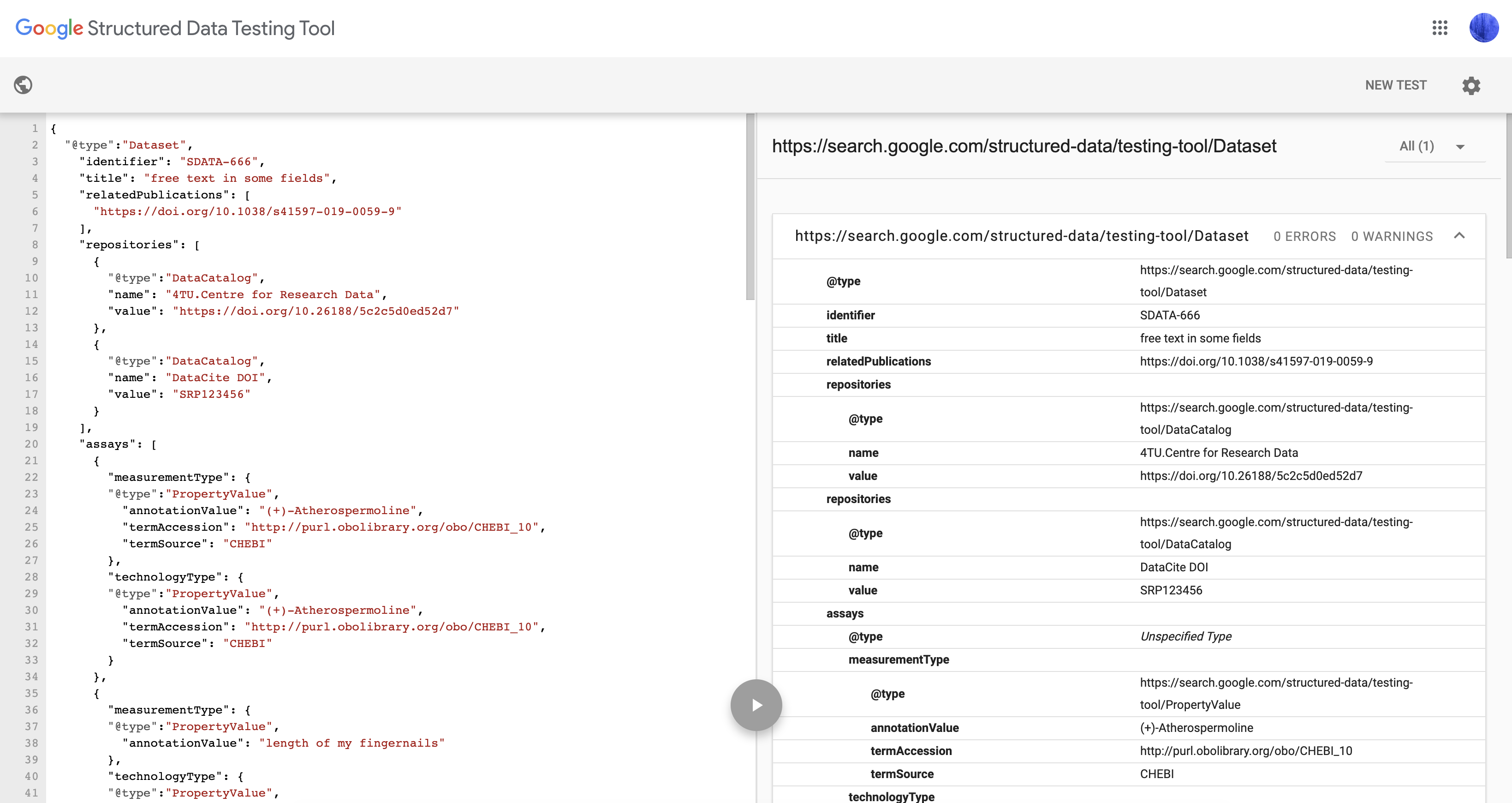
Fig. 9.2 Google Structured Data Testing Tool.¶
9.4.6. Bioschemas: trying to address the coverage gap¶
Schema.org development is mainly driven by commercial applications. The scientific use case was not very high until recently. The Covid-19 pandemic exposed the needs to find datasets and disease related information more effectively. This proves to be a good timing for the Bioschemas project, which has been running for a few years with the support of the EU-Elixir organization. Bioschemas focuses on making Schema.org more relevant for the life sciences community by providing:
typesfor life sciences entities such as chemicals, genes, and proteins.profilesthat identify the most pertinent properties for marking up a life sciences resources of a specific type to enable it to be more findable.
The main profiles currently specified by the Bioschemas organisation are as follows:
9.5. FAIRification Objectives, Inputs and Outputs¶
Actions.Objectives.Tasks |
Input |
Output |
|---|---|---|
9.6. Table of Data Standards¶
Data Formats |
Terminologies |
Models |
|---|---|---|
9.7. References¶
References
9.8. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Oxford |
|
Writing - Original Draft, Conceptualization |
|||
Heriot Watt University |
|
Writing - Original Draft, Writing - Review & Editing |
|||
ZB MED Information Centre for life sciences |
Writing - Review & Editing |