Prioritization of projects for FAIRification¶

Main Objectives¶
The main purpose of this recipe is:
To provide an overview of elements that could help users in prioritization and selection of potential projects, processes, or data for FAIRification. For each of these elements, we provide comparative benefits between different stages and justify the order of the stages required for FAIRification. Finally, we also highlight the reasons for making the data FAIR.
Introduction¶
With the increased awareness of the FAIR principles, the drive to implement them can be felt in projects and programs. However, considering the volume and variety of such projects and the finite nature of available resources, it is also necessary to establish a principled approach to prioritizing datasets for data FAIRification. The present recipe aims to provide insights into how to go about this process by showcasing essential criteria which have been considered and “battle-tested”.
The recipe is structured in the following way:
We begin by pointing out the reasons why one should to make their dataset FAIR.
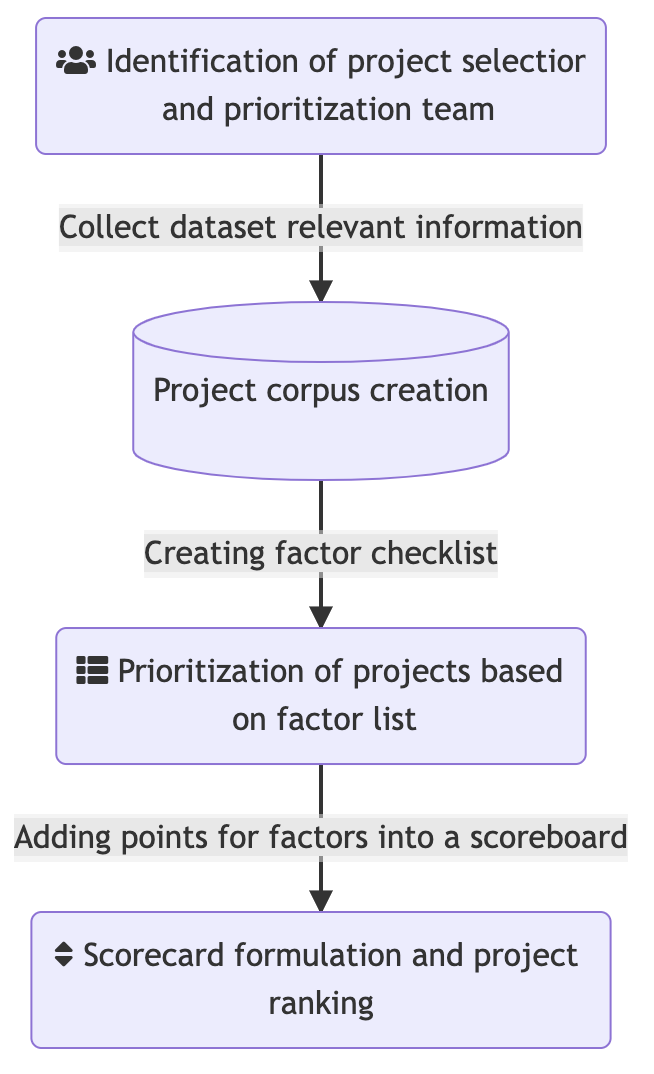
Following this, a brief overview of the dataset corpus formulation. Once “the team” has collected all the necessary data, it can now pass through the prioritization phase. Here, a thorough assessment of the dataset based on certain criteria is done. This assessment, in turn, leads to the development of a “scorecard”.
Finally, with the points each dataset has earned in the scorecard, a ranking can be established and projects or datasets can be prioritized.
Determining the need for FAIRification¶
Before understanding why and how to prioritize projects for the FAIR pipeline, it is essential to understand the need for FAIRification of data 2. The list below identifies key reasons why one should make data FAIR:
Increase impact and visibility:
Standardising published project/dataset metadata using a well-accepted metadata model and getting indexed by major community resources helps in increasing the visibility and impact of the data within the scientific community.
Harmonise data:
When creating a tool with the help of multiple independent resources, FAIRification can help in easing the integration of data sources, for instance with the help of a common terminology.
Encourages community collaboration:
The FAIRification process can attract communities together for potential collaboration as each of the independent communities would now have a structured data format to map their data for integration.
Prepare data for downstream tasks:
A FAIRified data is machine-readable and hence can potentially be used by software agents such as machine learning (ML) or artificial intelligence (AI) models for analysis with help of downstream.
Adds to the capitalization on research investment:
A FAIRified data is reusable, meaning that initial investment and newly generated data assets are protected but also that additional investment in redoing research can be avoided.
Additional reasons for the need of FAIRification encompass ethical reasons for doing so. These are more fully described in a dedicated recipe called Values of FAIR.
Dataset selection¶
To answer whether a project requires FAIRification or not, it is essential to first gather all relevant information about the projects and then analyze the resultant information in a stepwise manner.
Prior to digging deeper into the selection and prioritization process, it is essential to assemble a group of people who would take care of the prioritization process, the Project Selection and Prioritization (PSP) team. This team is an ensemble of people both within and outside the organization (if possible) to provide better directionality to the prioritization task.
The information that PSP team users can collect about the projects covered:
- Name
- Objective or aim
- Timeline (For e.g. start/end date)
- Types of partners involved (For e.g., industry and/or academic partners)
- Contact information of the leads
- Data and the data types involved
With the help of the above-mentioned list, the PSP team can formulate a filtering or prioritization schema. The next sections discuss different methods for achieving this.
Project prioritization¶
Once the basic information is collected, the PSP team can now describe projects through a scoreboard.
This scoreboard serves the purpose for prioritization of the projects that would go through the FAIRification process.
Enlisted below are the different aspects that can be considered while creating the scoreboard.
This list is not extensive and the PSP team can modify the criteria based on their needs.
1. Prioritization based on focus¶
When dealing with large number of projects, the PSP team can get an overview of the research area or focus area of the given project.
Specifically, projects from biomedical or clinical areas tend to be associated with a comorbidity or pathology, and the team can leverage this specific information to create a customised prioritization schema.
If the focus area of the project is not available directly, one makes use of manual curation or certain natural language processing (NLP) pipelines to extract this information from project documents.
One such example of the tool used by IMI is demonstrated on GitHub.
An in-house prioritization scheme can be established by FAIR experts for selection of relevant projects for the FAIRification process.
This involves a two-step approach:
- Identification of certain priority disease areas, such as COVID-19, neurodegenerative diseases, cardiovascular diseases, etc.
- Prioritizing projects falling into these priority areas compared to others.
2. Prioritization based on timeline¶
The process for FAIRification could be done either to the data present in a project or to a processing pipeline that is part of the project. Due to the interdependence of the data or process with the project, the time range at which a project runs is an important criteria to understand the availability of the data or pipeline. Taking a deeper look into the data dependency for the FAIRification process, a project can be divided into three stages of development: early stage, middle stage, and end stage.
A project is in early stages of development when the data requirements for the given project are being listed and simultaneously being collected. At this stage, the data availability is the lowest, and it is easier to design a data model, choose ontologies etc. that ensures creation of FAIR data by design.
In the middle stage, all the data relevant for the given project has been collected and now needs to be standardised for downstream tasks such as for predictions using machine learning approaches. This is a stage where there is maximum availability of data.
Lastly, in the end stage, data has either been deposited or handed over to the respective heads and the project is near its termination. Furthermore, it is at this stage that the risk of organisation restructuring is highest, with staff reassignment or departure. Hence, starting a FAIRification process at a project end stage could be the least favourable as this could place large demands in time and resources on key personnel, such as for corresponding data owners and data generators, at a time of effort wind down.
Hence, the best time of engaging a project into the FAIR pipeline would be dependent on the retrospective and prospective aspects of the project. The best time to FAIRify prospective projects is the early stage. This stage is the best time to define and layout metadata standards that need to be followed during the project’s trajectory. As a result, it eliminates many of the downstream logistical and financial problems. On the other hand, the best time to engage in FAIRification of retrospective projects is in the middle stage. This is because it is a data-rich stage and contact with both data owners and generators could be established for a better understanding of the data.
3. Prioritization based on partners¶
A project has the potential to involve a large number of people each coming from various institutions. Consequently, users can also consider the wider consortia involved as a criteria for prioritizing projects from a list of projects. In the end, the FAIRification process should benefit as many people as possible.
Thus, projects that have diverse partners involved (e.g. academic, industrial, start-up, and so on) should be prioritized over singleton partners, that is those projects that involve people from the same institute or industrial group. The main reason for this priority is the impact of the FAIRification process. Within an intra-organization group, the data generators, maintainers, and depositors might have the same terminology and definitions related to the data and hence, a FAIRification process would only be needed when the data has to be deposited on public repositories or databases. On the other hand, in an inter-organization group, definitions and terminologies aren’t likely to be consistent, and the transfer of data from data generators to depositors might be time-consuming. As a result, the FAIRification process would be beneficial by increasing transparency between intra-organizational groups.
4. Prioritization based on existence of Data Management Plan (DMP)¶
A data management plan (DMP) is a document that describes the life cycle of a data beginning from its generation, followed by processing and collection, then dissemination, and finally the usage (More details in Data Management Plan recipe). This established document gives the data owners and FAIR experts an overview of the resource under study. On the basis of this DMP document, a FAIRification process can be determined and established. In case of the absence of a DMP, the FAIR experts lack the ability to find the best FAIRification process for the given data thereby leading to inefficient results. Overall, the DMP plan would potentially point to the data regulatory aspect, considering the data usage as well as dissemination of the data into public resources. Thus, projects that have their DMP documents established should be prioritized over those projects that do not have one ready yet.
5. Prioritization based on data availability and access¶
Even when the data is available, it does not necessarily mean that the data is accessible, and thus it is essential to ensure both data availability and accessibility before the FAIRification process. In most situations, the data would only be accessible to users within the consortium, while in other situations the data is strictly restricted to data producers such as health records, especially for sensitive data.
The best practice in such situations is to have at least one member from the consortium in the FAIR experts team, the team involved in the FAIRification process. This enables easing the FAIRification process in 2 ways: first, it removes the limitation for data availability (in cases the data can only be accessed by an individual within the consortium) and second, it allows direct contact with data owners and generators, a guarantee for better understanding of the data.
When mentioned data accessibility, this could be broadly classified into three categories:
Accessing via web-interface - Here, the data is hosted by the data owner in a cloud system and the relevant data can be accessed using the web simply.
Programmatic access - Here, the data is made available via programmatic services such as REST API. This is mainly of interest to data handlers within the FAIR expert team who can with few lines of programmatic code access the data.
No access - Here, given the confidentiality and legal aspects involved in dealing with the data, certain data owners will be reluctant to provide access to the data. One such example in this case could be a potential lead compound in a pharmaceutical company. Here, the company would give no access to the data until they have patented the compound or given the compound to clinical trial.
In summary, projects that FAIR experts can get access to data should be at a higher priority than those that have limitations on data access.
6. Prioritization based on presence of data champions¶
Data champions can be defined as a group of people that have an expertise in dealing with certain processes, data, or pipeline. When dealing with specific processes or data types, it is beneficial if an expert who has experience in dealing with such processes or data already exists within the FAIR expert team.
Prioritization of projects with consideration of expertise required in dealing with FAIRification tasks should be done. Such projects can then have a predetermined timeline involved, making the step-by-step approach for accomplishing a FAIR process or data comparatively easy.
7. Prioritization based on data types¶
Each project may produce a range of data that may be available in a number of different formats. For instance, sequencing data can be in distributed in FASTQ format while associated metadata be described using INSDC SRA format or imaging data in DICOM format. It is therefore possible to rank projects based on this information and more precisely, one may use a resources such as FAIRsharing to do two things:
i. Identify the community approved data type format and terminologies supporting a data type
ii. Identify a funder or publisher recommended repository accepting this data type (e.g. EMBL EBI Array Express for Transcriptomics data)
Hence, projects that have the above two pointers addressed should be prioritized over those that do not.
In summation, each project gets a score based on the aforementioned factors and this score-based assessment of projects would in turn lead to development of a scorecard 4.
Prioritisation between different project-based factors¶
Along with the above criteria, two more factors play a crucial role in the prioritization process:
The first is the time management. Since the FAIRification process can depend on a number of factors, it is important to acknowledge the time required for the process to complete.
The second is risk management, with the assessment of potential roadblocks that could interfere essential. Such roadblocks should be identified and rectified if possible prior to starting a FAIRification process.
Each of these criteria have an independent stance and when creating a scoreboard, a personalized priority between these factors need to be made. For example, if people have data champions within their FAIRification team, they would prioritize data availability and access factor over the data champions factor.
Another prioritisation schema that could be used for intra-factor ranking could be the cost and value benefits of each of the factors 1. The cost factors refer to the set of indicators or aspects that influence the costs associated with the FAIRification process, while the value factors can be defined as the value proposition for performing the FAIRification. To provide a granular overview of this criteria, classification based on two factors, cost and value, has been shown in the table below.
Value criteria |
Cost criteria |
|---|---|
Project focus |
Data availability and access |
Data champion |
Availability of DMP |
Data Type |
Partners involved |
Project ranking and prioritisation¶
Overall, in the scorecard, each project is assigned a score based on certain criteria. To enable ranking of projects, an additive sum of each of these criteria should be used, thereby assigning each project with one final score. In the end, a descending ranking of the projects can be achieved, and the top projects can be selected for FAIRification by the PSP team and handed over to the people responsible for the FAIRification process.
The prioritisation and selection schema mentioned in this recipe was successfully adapted and applied for the FAIRification process within IMI 3. A snapshot of the scorecard used within IMI for selecting and prioritising FAIRification projects can be seen below 4.

Fig. 13 Score card template.¶
Conclusion¶
Faced with a larger number of projects needing FAIRification, it is necessary to establish a process for ranking and prioritizing these projects. The recipe, besides reminding the benefits of making their data FAIR, provided suggestions for assisting in establishing a prioritization procedure. Hence, the aim of the recipe was to provide the readers with a wider perspective of criteria they could use for ordering projects or datasets for FAIRification and enable them to personalize the ranking of factors based on their needs or requirements. Additionally, it provides the readers with a scorecard template that may be translated and used for their use cases.
What to read next section¶
References¶
Reference
- 1
Ebtisam Alharbi, Rigina Skeva, Nick Juty, Caroline Jay, and Carole Goble. Exploring the Current Practices, Costs and Benefits of FAIR Implementation in Pharmaceutical Research and Development: A Qualitative Interview Study. Data Intelligence, 3(4):507–527, 10 2021. URL: https://doi.org/10.1162/dint\_a\_00109, arXiv:https://direct.mit.edu/dint/article-pdf/3/4/507/1968563/dint\_a\_00109.pdf, doi:10.1162/dint_a_00109.
- 2
Tony Burdett, Mélanie Courtot, Fuqi Xu, Nick Juty, Jolanda Strubel, Wei Gu, Danielle Welter, Karsten Quast, and Dorothy Reilly. FAIRplus: D3.3 Report on IMI projects for data types and current technical solutions. January 2021. URL: https://doi.org/10.5281/zenodo.4428721, doi:10.5281/zenodo.4428721.
- 3
Ola Engkvist, Philip Gribbon, Vassilios Ioannidis, Manfred Kohler, David Henderson, Andrea Zaliani, Gesa Witt, and Dorothy Reilly. FAIRplus: D1.3 The first 15 IMI data sets selected and available for inclusion in WP 2 - 4 processes. January 2021. URL: https://doi.org/10.5281/zenodo.4428746, doi:10.5281/zenodo.4428746.
- 4(1,2)
Andrea Zaliani, Gesa Witt, Phil Gribbon, Yojana Gadiya, Vassilios Joannidis, and Manfred Kohler. FAIRplus template for project prioritization scorecard. December 2021. URL: https://doi.org/10.5281/zenodo.5782838, doi:10.5281/zenodo.5782838.
Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
Fraunhofer Institute |
Writing - Original Draft, Editing, Conceptualization |
||||
David Henderson |
Bayer AG |
Writing - Review & Editing |
|||
University of Luxembourg |
|
Writing - Review & Editing |
|||
Fraunhofer Institute |
Writing - Review & Editing |
||||
University of Oxford |
|
Writing - Review & Editing |