2. Building a catalogue of datasets¶

2.1. Main Objectives¶
The main purpose of this recipe is:
To detail the key elements for the creation of a data catalogue to enable data findability in an organisation.
We will cover the following points:
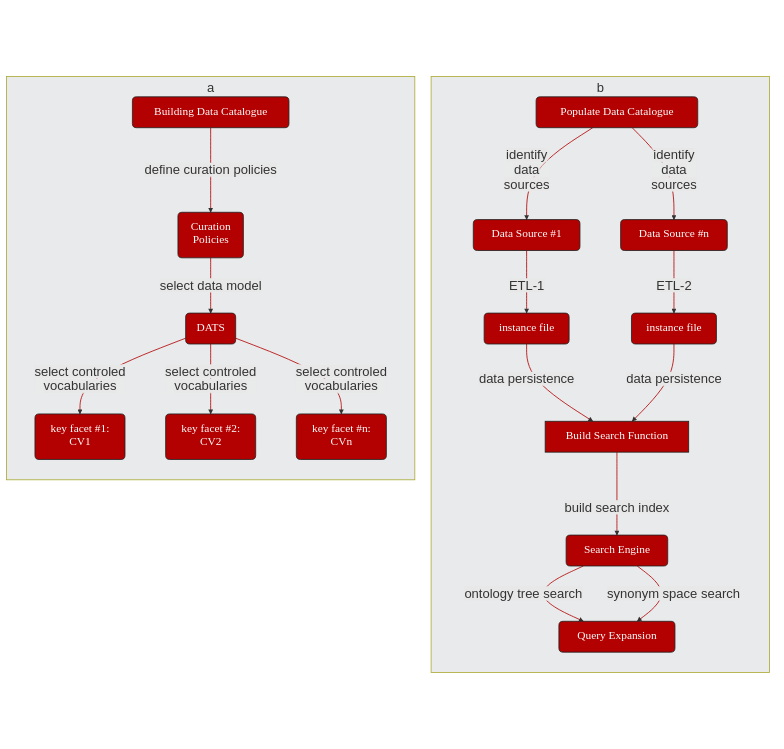
metadata model selection
annotation with controlled vocabularies
ETL
data loading
data indexing
facet oriented searching
minting of stable, persistent and resolvable identifiers
2.3. Capability & Maturity Table¶
Capability |
Initial Maturity Level |
Final Maturity Level |
|---|---|---|
Findability |
minimal |
repeatable |
Interoperability |
minimal |
repeatable |
2.4. User Story¶
For role.Data Scientists, it is essential to be able to action.identify and action.discover datasets of potential relevance in the context of action.data integration and action.meta-analytical work.
For role.Database Managers, a lightweight solution is needed to support a shallow indexing supported fast ingest without intense curation, but good potential for data discovery. Works should rely on approved data standards.
For role.lab scientists, the key is to have a minimal burden when having to action.deposit a dataset to an institutional archive or simply action.register to dataset to the data catalogue.
2.5. Main body of the recipe¶
2.5.1. What is a Data Catalogue?¶
A Data Catalogue is a resource meant to allow fast identification of Data set. In keeping with the familiar notion of catalogue, (be it that of an exhibition or that of brand products), the notion of data catalogue needs to be understood as the compendium of short descriptive metadata elements about an actual set of data. The Data Index or Data Catalogue does not store the datasets themselves but provides information about where the datasets can be obtained from. Therefore, Data Catalogues are often used to index the content of ‘Data Repositories and ** Data Archives**, which provide hosting solutions for the actual datasets, which are often organized (but not always)’ around specific data types or data production modalities (e.g. NMR Imaging, Confocal microscopy imaging, Nucleic Acid sequence archives and so on.)
2.5.2. What are the standards supporting establishing a data catalogue?¶
Data Catalogues have been identified as critical infrastructure and therefore a number of model exist to support their implementation.
DATS: The Data Article Tag Suite model has been developed during the NIH-BD2K projects and underpins the datamed catalogue, the aim of which was to produce a prototype of a Pubmed for Datasets.
DCAT: In the world of semantic web technologies, The W3C DCAT specifications (v1 and the newly released version 2) provide a vocabulary to express data catalogue metadata in RDF.
Schema.org: The vocabulary developed by the consortium of search engines has defined a metadata profile for Dataset, Data Catalogue
2.5.3. How are Data Catalogue populated?¶
A number data Indexes/Data Catalogue are populated by harvest Dataset metadata from primary Data Repositories or harvesting JSON-LD files served by these same pages for rapid, shallow indexing. The former method is often richer but requires more
2.5.4. What are examples of Data Catalogues?¶
Commercial solutions:
Open source solutions:
2.6. Table of Data Standards¶
Data Formats |
Terminologies |
Models |
|---|---|---|
JSON |
||
RDF |
DCAT v1 |
DATS |
RDF |
DCAT v2 |
DATS |
JSON-LD |
Schema.org |
2.7. Conclusion¶
This recipe introduced the general concept of data catalogue and why they constitute a key capability to deliver data discoverability.
2.7.1. What should I read next?¶
We encourage the readers to either delve deeper into the specific of data catalogues by consulting the following recipes
For the readership interested in finding out about additional capabilities needed to enhance other aspects of FAIR such interoperability and reusability, see the following:
2.8. References¶
References
2.9. Authors¶
Authors
Name |
ORCID |
Affiliation |
Type |
ELIXIR Node |
Contribution |
|---|---|---|---|---|---|
University of Oxford |
|
Writing - Review & Editing |
|||
University of Oxford |
|
Writing - Review & Editing, Funding acquisition |